前言
语音合成系统分为前端和后端,前端负责分词、词性、多音字标注等文本特征信息提取;后端模块根据前端提取的文本特征完成语音生成。从技术角度,传统后端模块又可以细分为拼接系统和参数系统,拼接系统和参数系统各有优缺点,详细对比可以参照 AI Talk 的上一篇文章 基于深度学习的语音合成技术进展 。
传统的语音合成系统,都是相对复杂的系统,比如,前端模块需要较强的语言学背景知识,不同语言的语言学知识差异明显,需要特定领域的专家支持,增加了系统构建的难度。参数系统的后端模块需要对语音的发声机理以及信号处理有一定的了解。由于传统参数系统建模时存在信息损失,限制了合成语音表现力的进一步提升。而拼接系统则对语音数据库要求较高,同时,需要人工介入制定很多挑选规则和参数,以保证拼接合成的效果和稳定性。
这些问题促使端到端语音合成的出现,研究者希望能够合成系统能够尽量的简化,减少人工干预和对语言学相关背景知识的要求。端到端合成系统直接输入文本或者注音字符,系统输出音频波形。前端模块得到极大简化,甚至可以直接省略掉。端到端合成系统相比于传统语音合成,降低了对语言学知识的要求,可以方便的在不同语种上复制,批量实现几十种甚至更多语种的合成系统。借助于深度学习模型的强表达能力,端到端语音合成系统表现出令人惊艳的合成效果和强大丰富的发音风格与韵律表现力。
本文将向您介绍云知声在端到端语音合成方向的探索和尝试,这其中既包括对已有算法的理解和复现、又包括云知声结合自身对算法的调整和改进。如果您是语音合成爱好者,希望了解语音合成行业发展和最新技术的现状,建议您试听文中附带 Samples,这些 Samples 代表这当前实验室环境下,语音合成韵律和音质的最佳水平。如果您是语音合成或机器学习从业者,希望了解技术细节,建议您从头阅读文章,如有问题欢迎留言或私信。
Tacotron
Tacotron 是第一个真正意义上端到端的语音合成系统,它输入合成文本或者注音串,输出 Linear-Spectrum ,再经过 Griffin-Lim 转换为波形,一套系统完成语音合成的全部流程。
Tacotron 前后推出两代,Tacotron2 主要的改进是简化了模型,去掉了复杂的 CBHG 结构,同时更新了 Attention 机制,提高了对齐稳定性。Tacotron 和 Tacotron2 师出同门,总体思路是一样的,本文以初代 Tacotron 为例讲解。
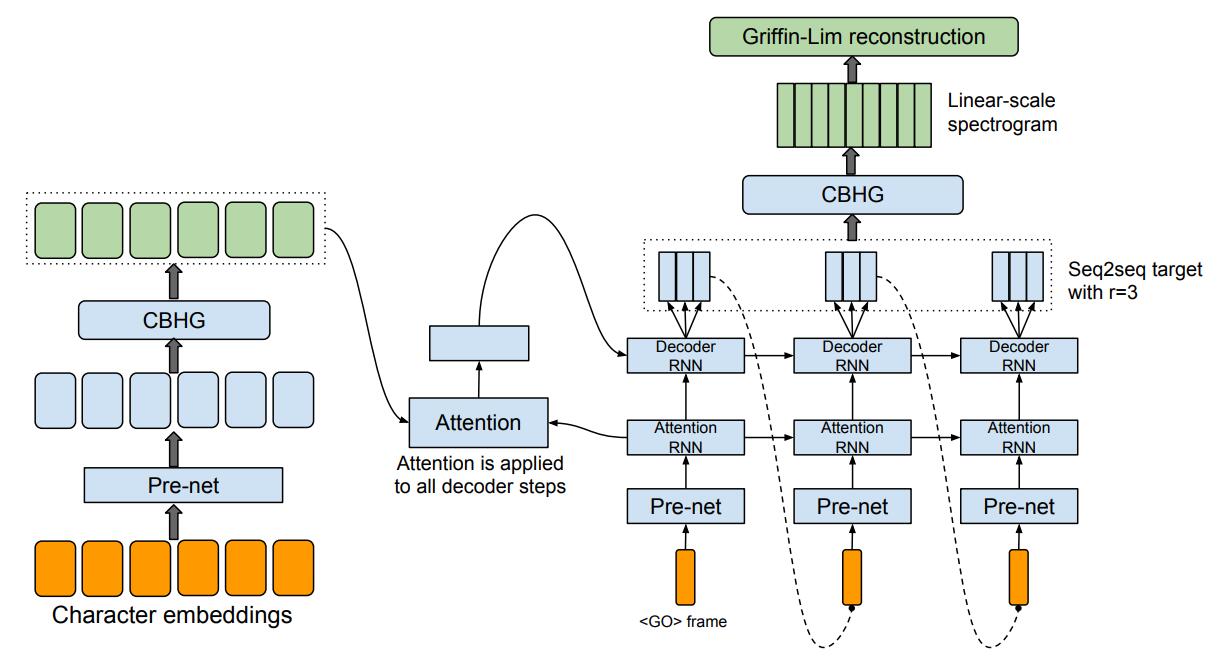
图1: Tacotron 模型结构
图1 记录了 Tacotron 的整体结构,黄色代表输入,绿色代表输出,蓝色代表网络。网络部分大体可分为 4 部分,分别是左:Encoder、中:Attention、右下:Decoder、右上:Post-processing。其中 Encoder 和 Post-processing 都包含一个被称为 CBHG 的结构,CBHG 结构的详细介绍可以参照上一篇文章 “基于深度学习的语音合成技术进展” 。Encoder、Attention、Decoder 共同构成了经典的 Seq2seq 结构,所以 Tacotron 也可以看做是一个 Seq2seq + Post-processing 的混合网络。
Tacotron 输入可以有多种选择,以中文和英文合成系统为例:
1. 英文文本,训练英文模型,最直观的想法是直接将英文文本当做输入,Tacotron1 也是这么做的。但这样可能会引入一些问题,比如未登录词发音问题。
2. 英文注音符,用英文注音符(比如 CMUDict )作为输入可以提高发音稳定性,除了注音词典,还可以引入注音前端,增强对模型的控制。
中文拼音,由于中文汉字数量多,且存在大量多音字,直接通过文本训练
3. 中文拼音,由于中文汉字数量多,且存在大量多音字,直接通过文本训练是不现实的。所以我们退而求其次,通过拼音训练模型,拼音有注音前端生成,既去掉了汉字的冗余发音又提高了模型的可控性。
4. 中文|英文 IPA (International Phonetic Alphabet) 音标,IPA 音标是一种更强的注音体系,一套注音体系可以标注多种语言。对于中文,IPA 音标的标注粒度比拼音更细,实验中,我们观察到用 IPA 作为输入,可以略微提升对齐稳定性。另外,在中文发音人+英文发音人混合训练试验中,我们观察到了一个有意思的现象:由于中英文 IPA 标注中共享了部分发音单元,导致跨语种发音人可以学会对方的语言,也就是中文发音人可以合成英文,英文发音人可以合成中文。在这个联合学习过程中存在着迁移学习的味道。
根据不同的用途,Tacotron 可以输出 Linear-Spectrum 或 Mel-Spectrum,如果使用 Griffin-Lim 需要 Tacotron 输出 Linear-Spectrum;如果使用 WaveNet 做 Vocoder ,则 Tacotron 输出 Linear-Spectrum 或 Mel-Spectrum 均可,但 Mel-Spectrum 的计算代价显然更小,Tacotron2 中,作者使用 80 维 Mel-Spectrum 作为 WaveNet Vocoder 的输入,在云知声我们使用 160 维 Mel-Spectrum 。
Seq2Seq 模块:Seq2Seq 本质上是学习序列到序列映射的强大模型,其已经在多个不同领域(NMT、CHAT、ASR等)取得了成功。Tacotron 套用了这套框架。在 Seq2Seq 模块中,输入是注音序列,输出是 Mel-Spectrum 序列,引入低维 Mel-Spectrum 的目的是帮助 Attention 收敛。模型里还包含很多 tricks 包括引入 CBHG 模块,Decoder 模块每一时刻同时输出多帧等等,这里就不一一赘述。
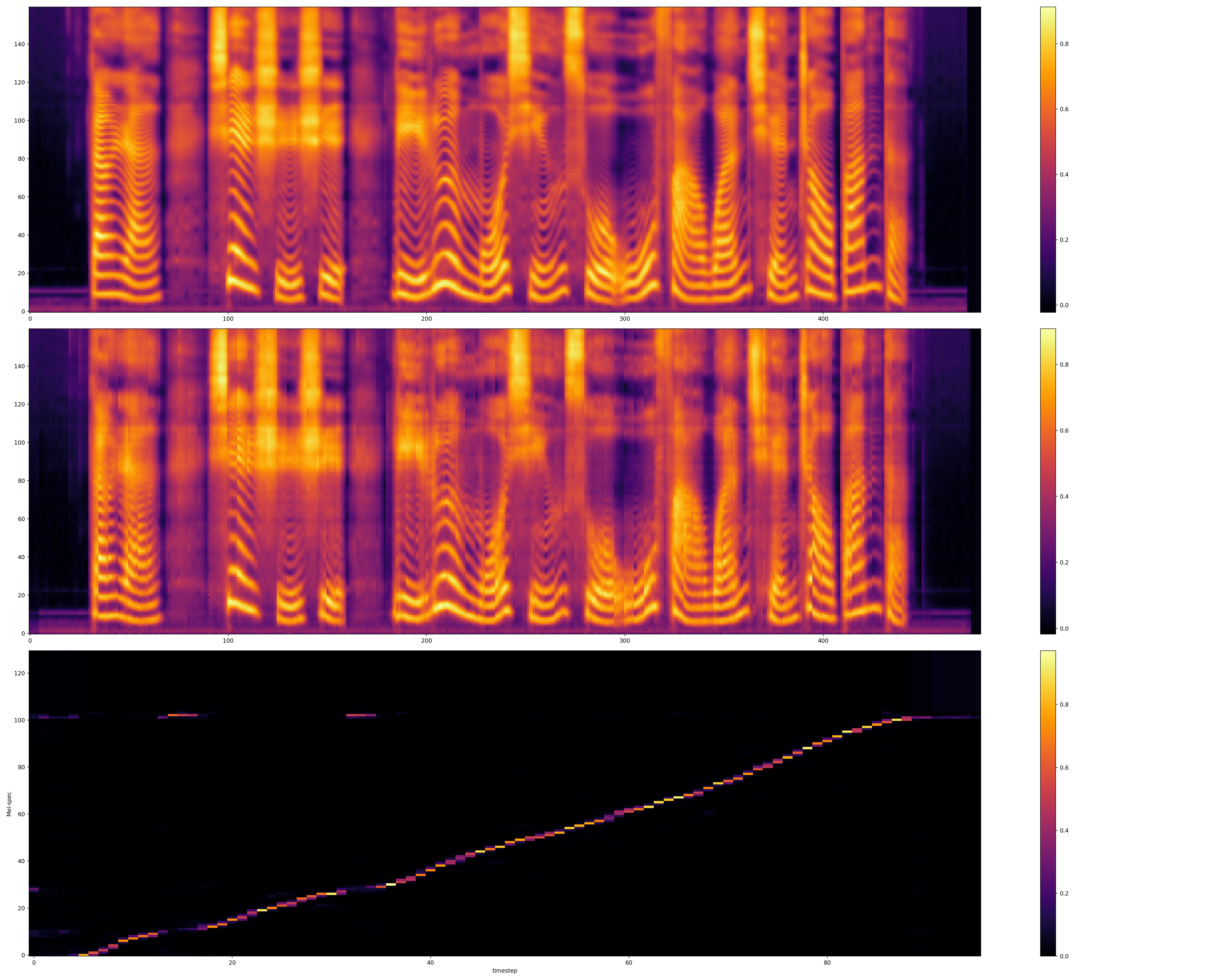
Post-processing 模块:Post-processing 是另一个很重要的模块,在 Tacotron + WaveNet Vocoder 框架下,Post-processing 模块的输入是 Seq2Seq 模块输出的 Mel-Spectrum,输出是也是 Mel-Spectrum,看起来多此一举,但却有意义。Seq2Seq 的框架决定了 Decoder 只能看见前面的若干帧,它对未来一无所知,而 Post-processing 则可以看见前后若干帧,参考信息更多,理论上生成质量也更高。我们可以在实验中观察 Post-processing 的作用。 下图中,从上到下依次是,Post-processing 输出 Mel-spec;Decoder 输出 Mel-spec;对齐。可以看到 Post-processing 输出的 Mel-spec 更平滑高频细节还原更清晰。
图2: 上:Post-processing Mel-Spectrum 中:Seq2Seq Mel-Spectrum 下:Attention
实时解码 tricks (CPU)
在 Tacotron1 中,作者使用 Griffin-Lim 算法,从 Linear-Spectrum 中恢复相位,再通过 ISTFT 还原波形,Griffin-Lim 的优点是算法简单,可以快速建立调研环境,缺点是速度慢,很难在 CPU 上做到实时,无法实时解码也就意味着系统无法在生产环境使用。
幸运的是我们可以找到一些稍显复杂但有效的方法,加速解码。
1. SPSI (Single Pass Spectrogram Inversion),顾名思义,是一种没有迭代的快速 Spectrogram Inversion 算法,速度飞快,但音质通常比 Griffin-Lim 差。
2. Griffin-Lim 是一个迭代算法,可以通过增加迭代数量提高合成音质,在实验中我们通常进行60轮迭代以保证音质稳定。
SPSI 速度快但效果堪忧;Griffin-Lim 效果尚佳,但速度慢,有没有办法结合两者的优点呢,答案是肯定的。我们的方案效果可以与 60轮 G&L 打平,同时可以在 CPU平台上将实时率做到令人满意的指标(GPU 平台,性能还会翻几倍 )。需要注意的是,性能指标在 Tensorflow 环境下获得的,并没有包含其他深入的工程化工作。
Samples
你觉得上面的 Samples 听感如何呢?韵律还不错,音质乍一听也还好,但似乎又有些问题,主要表现在沉闷,不锐利。
没错,通过 Griffin-Lim 生成波形的频谱过于平滑、空洞较多,听感不佳。没关系,在下一节中我们将想办法解决这一问题。
Vocoder
通过上面一些列努力我们已经可以将 Tacotron 的 CPU 解码速度做到实时了,但音质上始终有些欠缺。种种迹象表明,Griffin-Lim 算法是音质瓶颈,经过一些列工作尤其是 Tacotron2 ,人们逐渐意识到,Mel-Spectrogram 可以作为采样点自回归模型的 condition,利用强大的采样点自回归模型提高合成质量。
目前公认的效果有保障的采样点自回归模型主要如下几种,1) SampleRNN、2)WaveNet、3)WaveRNN。我们分别从头实现了 SampleRNN 和 WaveNet ,下面我们将逐一介绍
SampleRNN
模型
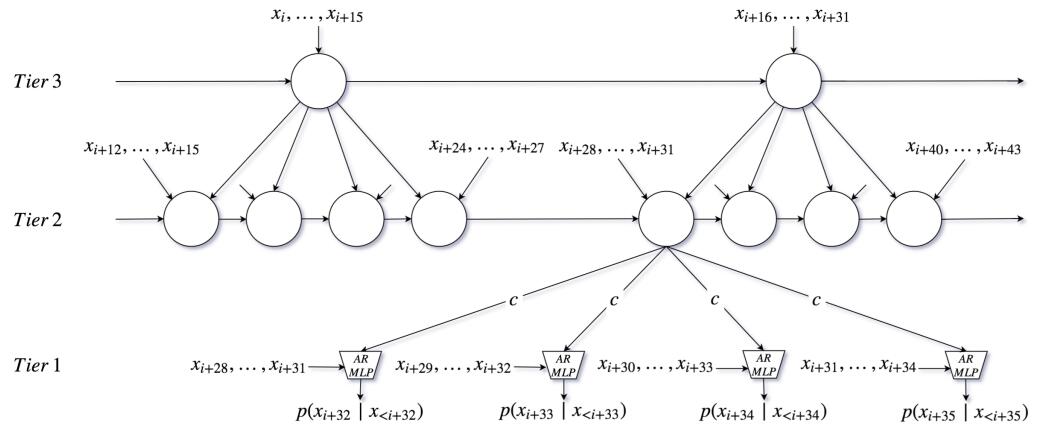
图3: SampleRNN 模型结构
SampleRNN 是一个精心设计的 RNN 自回归模型。标准的 RNN 模型包括 LSTM、GRU,可以用来处理一些长距离依赖的场景,比如语言模型。但对于音频采样点这样的超长距离依赖场景(比如:24k采样率,意味着 1s 中包含 24000 个采样点),RNN 处理起来已经非常困难了 。SampleRNN 的作者,将问题分解,分辨率由低到高逐层建模,例如图中,Tier3 层每时刻输入16个采样点,输出状态 S1;Tier2 层每时刻输入 4 个采样点,同时输入 Tier3 输出的 S1,输出状态 S2 ; Tier1 层每时刻输入 4 个采样点,同时输入 Tier2 输出的 S2,输出一个采样点,由于 Tier1 没有循环结构,同一时刻可以输出 4 个采样点。
Samples
下面是 Unconditional SampleRNN 合成的一段语音,由于是 Unconditional 所以没有语义内容,但保留了发音、音色以及韵律风格,我想你一定听出了他是谁吧?
如果有兴趣,可以点击 SampleRNN Samples,在里面你能找到总长度为 1小时 的 Samples。
总体来看模型的波形生成能力相当了得,发音、音色以及韵律风格的还原度都非常高。但 SampleRNN 也存在一些问题,最主要的是训练收敛速度太慢了,导致调参优化效率低下,我们将在下一节介绍另一个采样点自回归模型 WaveNet,相比 SampleRNN ,WaveNet 不但保留了高水平的波形生成能力,而且还提升了训练速度,单卡训练一天就能获得较好的效果。
WaveNet
模型
图4: 采样点自回归 WaveNet
图4, 描述了 WaveNet 这类采样点自回归模型的工作方式,模型输入若干历史采样点,输出下一采样点的预测值,也就是根据历史预测未来。如果你对 NLP 较为熟悉,一定会觉得这种工作方式很像语言模型,没错,只不过音频采样点自回归更难一些罢了,需要考虑更长的历史信息才能保证足够的预测准确率。
WaveNet 最初由 DeepMind 推出,是基于 CNN 的采样点自回归模型,由于 CNN 结构的限制,为了解决长距离依赖问题,必须想办法扩大感受野,但扩大感受野又会增加参数量。为了在扩大感受野和控制参数量间寻找平衡,作者引入所谓“扩展卷积”的结构。如上图所示,“扩张卷积”,也可以称为“空洞卷积”,顾名思义就是计算卷积时跨越若干个点,WaveNet 层叠了多层这种 1D 扩张卷积,卷积核宽度为 2 (Parallel WaveNet 为 3),Dilated 宽度随层数升高而逐渐加大。可以想象,通过这种结构,CNN 感受野随着层数的增多而指数级增加。
训练好了 WaveNet ,我们就可以来合成音频波形了。但是,你会发现这时合成的音频完全没有语义信息,听起来更像是鹦鹉学舌,效果就如上一节 SampleRNN 的样例一样。 要使 WaveNet 合成真正的语音,那么就需要为其添加 condition ,condition 包含了文本的语义信息,这些语义信息可以帮助 WaveNet 合成我们需要的波形,condition 的形式并不唯一,但本文中我们只介绍 Mel-Spectrum condition 。
Mel-Spectrum condition
为什么要引入 Mel-Spectrum condition 呢?有两个原因:其一是为了和 Tacotron 打通,Tacotron 的输出可以直接作为 WaveNet 的输入,构成一套完整的端到端语音合成流水线;其二是因为 Mel-Spectrum 本身包含了丰富的语音语义信息,这些语音语义信息可以支持后期的多人混合训练、以及韵律风格迁移等工作。
下面我们将着重介绍如何在模型中融入 Mel-Spectrum condition 。
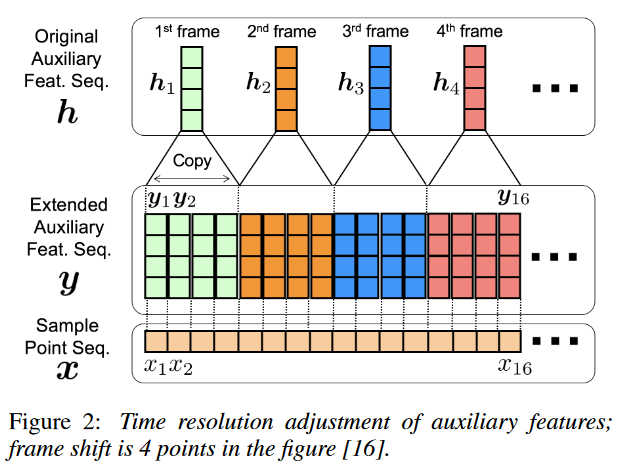
由于采样点长度和 Mel-Spectrum 长度不匹配,我们需要想办法将长度对齐,完成这一目标有两种方法:一种是将 Mel-Spectrum 反卷积上采样到采样点长度,另一种是将 Mel-Spectrum 直接复制上采样到采样点长度,两种方案效果差异很小。我们希望模型尽量简洁,故而采用第二种方法,如图6所示。
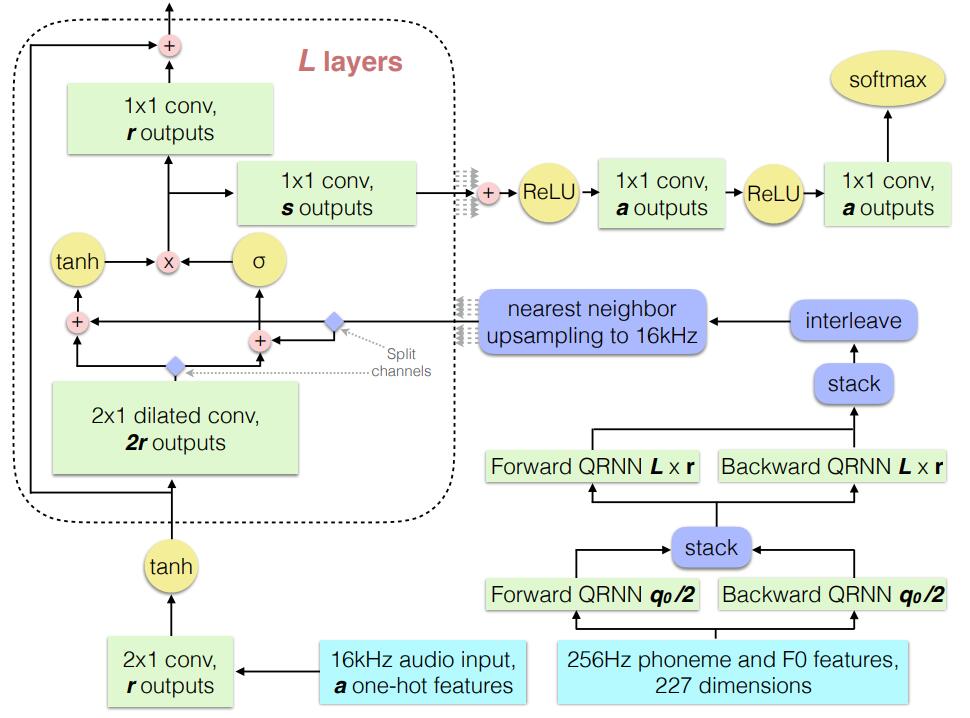
方便起见,我们借用 Deep Voice1 (图5)来说明。经过复制上采样的 Mel-Spectrum condition,首先需要经过一个 1x1 卷积,使 Mel-Spectrum condition 维度与 WaveNet GAU 输入维度相同,然后分两部分累加送入 GAU 即可,注意,WaveNet 每层 GAU 都需要独立添加 Mel-Spectrum condition。
图5: Mel-Spectrum condition 计算方法
图6: Mel-Spectrum 时间分辨率对齐
训练加速 tricks
WaveNet 中使用 8-bits 量化 μ-law 压缩,输出层采用 softmax,我们的实验表明,8-bits μ-law 压缩,会造成无法消除的背景噪音,影响听感。
Tacotron2 和 Parallel WaveNet 中 使用 MoL 代替 softmax 作为输出层,同时直接输出波形的采样值(取消 μ-law 压缩)。我们的跟进实验验证了该方法的有效性,背景噪音消除,音质得到有效提高。但训练时间大大延长,单发音人往往需要 5~7 天才能收敛,效率低下,这迫使我们寻找更高效的训练方法。
云知声的方案对两者进行了折中,试验表明,该方案合成语音听感上和 MoL 无差别(虽然理论上还是有损的),但训练时间大大压缩,一般 24 小时内就可以训练得到不错的模型。
Samples
下面我们来见证一下 WaveNet + Mel-Spectrum 组合的惊人能力,这是一段 WaveNet + Ground truth Mel-Spectrum 的合成语音,Mel-Spectrum 出自测试集,你能听出是谁么?
需要说明的是,整个训练集来自网络公开数据,时间跨度很长,听起来录音似乎来自多种不同设备,有损压缩,压缩比也不尽相同,造成不同录音片段在听感和谱图上都有明显差异,但这些似乎丝毫没有影响 WaveNet 的学习,它几乎完美的从 Mel-Spectrum 还原了波形。
WaveNet 有很多优点,训练快、效果好、网络结构清晰简洁。但 WaveNet 也引入了新问题:inference 性能差,在 CPU 平台通常需要数十秒时间合成一秒语音,这让商业化几乎不可能。
针对这一问题,DeepMind 推出了 WaveNet 加速方案 Parallel WaveNet,Parallel WaveNet 将 inference 速度提升上千倍,我们也在这里做了相应的尝试,后面会做介绍,不过在此之前,我们可以先将 Tacotron 和 WaveNet 组合起来,看看效果如何。
Tacotron + WaveNet Vocoder
在上一节中我们已经训练好了一个带 condition 的 WaveNet,这个模型可以根据输入的 Mel-Spectrum 还原波形,但要构建一个完整的 TTS 系统,我们还需要生成 Mel-Spectrum 。这个任务当然要交给 Tacotron 了,我们现在将 Tacotron 和 WaveNet Vocoder 组合起来,整体的流程是,注音文本送入 Tacotron 输出 Mel-Spectrum, Mel-Spectrum 再送入 WaveNet 合成波形。下面,我们会放出一些 Samples,请大家体会一下合成的效果。
Samples
TTS or Human
下面包含了几对语音,真人和模型分别说同一句话,你能分辨出哪些是真人,哪些是模型么?
AB Test
| AB Test |
| 参数合成 |
Tacotron + Griffin-Lim |
Tacotron + WaveNet |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
下面包含三组语音,分别来自参数合成、Tacotron + Griffin-Lim、以及 Tacotron + WaveNet。你认为哪一组听感更好?
下篇预告
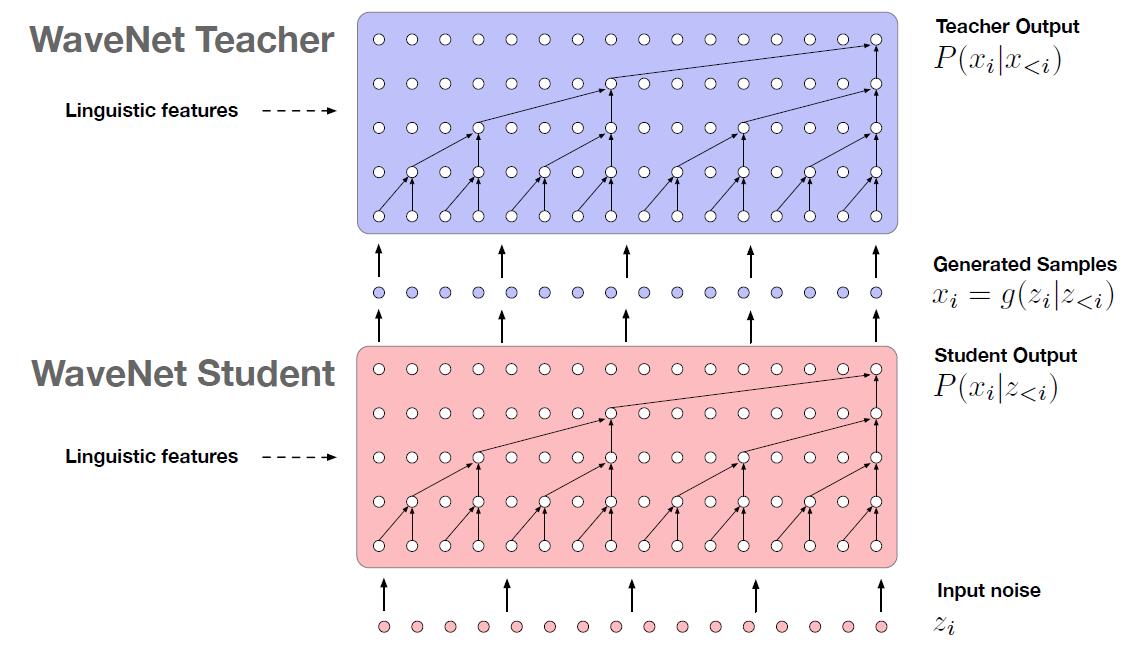
如前所述,DeepMind 推出的 Parallel WaveNet,使模型 的 inference 速度提升上千倍,性能跨过了商业化门槛。云知声对此也进行了大量实验,但关于 Parallel WaveNet 的实现细节,还请关注“下篇”的分享,我们的实现与 DeepMind 有不同哦!敬请期待。
图7: Parallel WaveNet
Samples
下面的 Samples 是自回归 WaveNet 和 Parallel WaveNet 的对比。据我们所知,这是业界首次公开的中文 Parallel WaveNet 样例。
| Parallel WaveNet |
| Autoregression WaveNet |
Parallel WaveNet |
|
|
|
|